Cette avancée met en lumière le potentiel de l’apprentissage par renforcement à grande échelle sur des modèles fondamentaux solides.
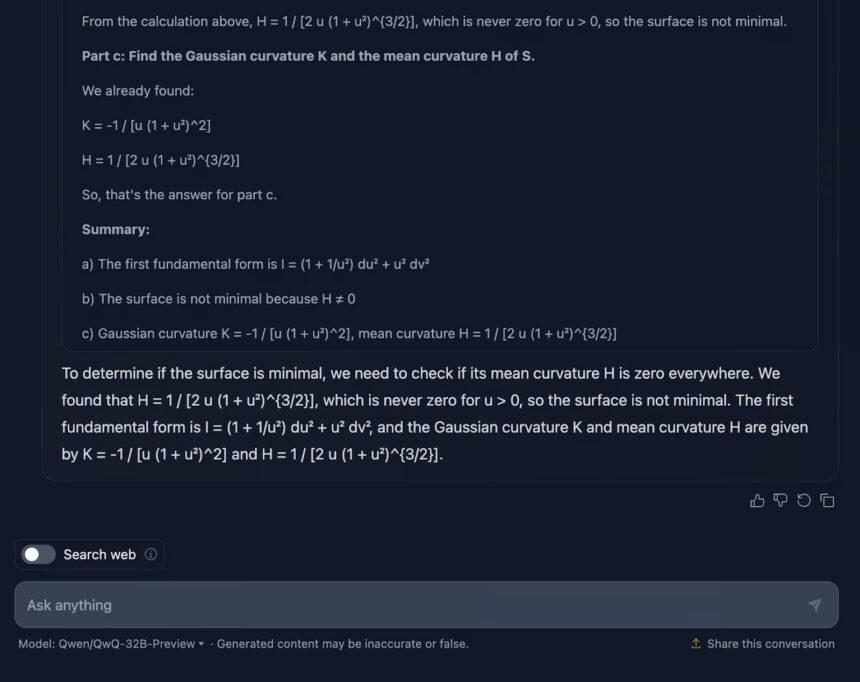
Le QWQ-32B a été évalué dans divers benchmarks, montrant des performances remarquables par rapport à d’autres modèles leaders, et ouvrant la voie à une utilisation plus efficace de l’IA dans des domaines variés tels que les mathématiques, le codage et la résolution de problèmes.
L’approche de l’équipe QWEN impliquait un processus de renforcement en plusieurs étapes, basé sur des récompenses, permettant d’améliorer les capacités de raisonnement du modèle.
Avec une approche axée sur l’extension des performances générales, la mise à l’échelle de l’apprentissage par renforcement ouvre la voie à des avancées significatives dans le domaine de l’intelligence artificielle.
Le modèle QWQ-32B est désormais disponible en open source, marquant une première étape dans la quête de l’équipe pour intégrer de manière encore plus poussée les agents et le renforcement pour un raisonnement à long terme plus efficace.